
사용 데이터셋 (출처):
https://www.kaggle.com/datasets/die9origephit/amazon-data-science-books/data
Amazon Data Science Books Dataset
Amazon most popular data science books
www.kaggle.com
1. 데이터셋 불러오기
import pandas as pd
### CSV 파일 불러오기
book_DataFrame = pd.read_csv("/Users/lynnhayley/Desktop/Datascience/CSV files/1. Pandas Practice/final_book_dataset_kaggle2.csv", thousands = ',')
###head로 데이터프레임 어떻게 생겼는지 확인!
print(book_DataFrame.head())
pd.read_csv로 csv파일을 불러왔습니다. thousands = ',' 를 사용해 콤마를 사용한 숫자들에 대해 수로 인식할 수 있게끔 하였습니다. 그리고 .head()를 사용해 데이터프레임이 어떻게 생겼는지 확인해 보았습니다.
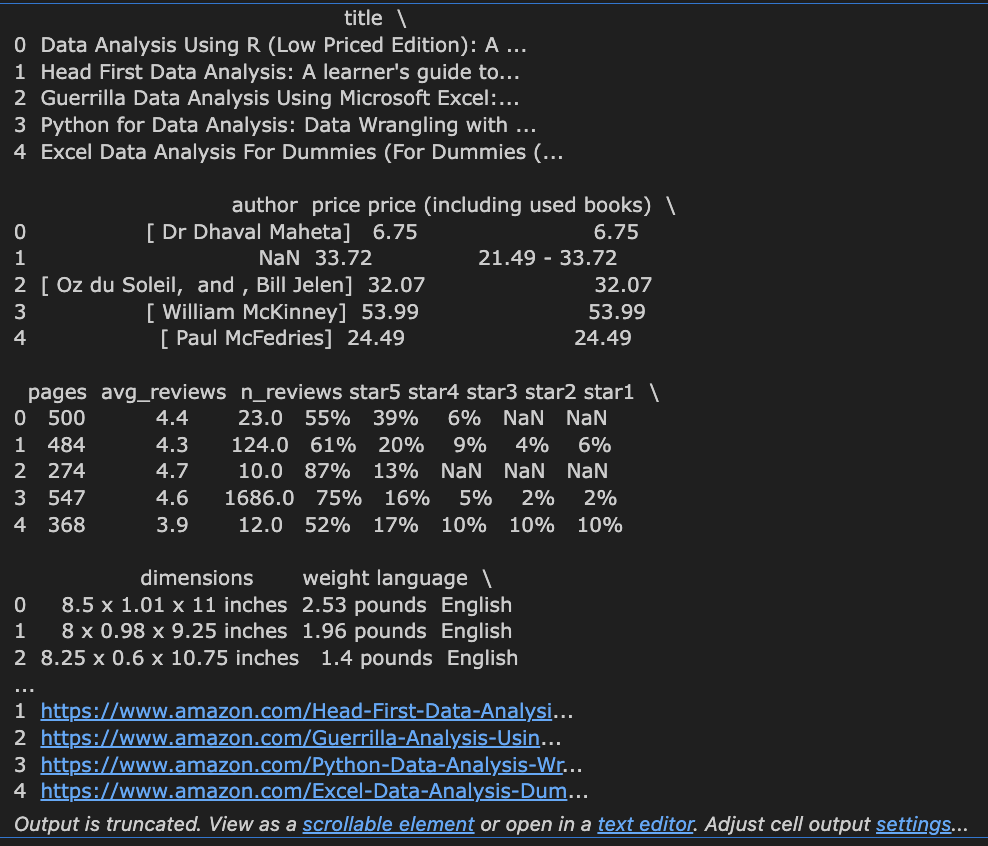
데이터셋은 이렇게 생겼습니다. 여기서 생각해볼만한 포인트는,
1. 이 데이터셋을 가지고 무엇을 할 것인가?
2. 이 데이터셋에서 필요한 부분은 어디인가?
3. 내가 원하는 결과 (1번 문제의 답)을 가져오기 위해서는 어떤 전처리 과정이 필요한가? 입니다.
우선 저는 이렇게 생각했습니다.
1. 저는 이 데이터셋을 가지고 네 가지를 확인하려 합니다.
a) 평균 별점이 어떻게 분포되어 있는가?
b) 각 책 별로 리뷰가 얼마나 많이 달려 있는가?
c) 각 책 별로 평점 별점 5점, 4점, 3점은 얼마나 비율을 차지하고 있는가? 그 비율이 얼마나 되는가?
d) 책의 가격과 페이지수 간의 상관관계가 있을까?
2. 필요한 부분은 어디인가?
dimension이나 weight, URL 등의 부분은 없어도 될 듯 합니다. 저는 star1열까지만 가져가려고 합니다. 그리고 이 수많은 행을 다 처리하면 좋겠지만, 이번 프로젝트에서는 20개의 행만 가져가려 합니다.
3. 전처리 과정은 어떤 것이 있을 것인가?
일단 대강 보았을 때, missing values에 대한 처리가 필요해 보입니다. 그리고, 데이터의 자료형을 파악해 그 자료형을 변환하는 과정도 필요해 보입니다.
그럼, 차근차근 프로젝트를 진행해 보도록 하겠습니다.
2. 전처리 과정
### 결측치 확인하기
print(book_DataFrame.isna().sum())
### author에 결측치 있는 경우 행을 없애도록 할게요!
book_DataFrame = book_DataFrame[book_DataFrame['author'].notna()]
### 결측치를 0으로 대체하도록 하겠습니다.
book_DataFrame = book_DataFrame.fillna(0)
book_DataFrame
먼저 결측치에 대해서 처리를 해 보았습니다.
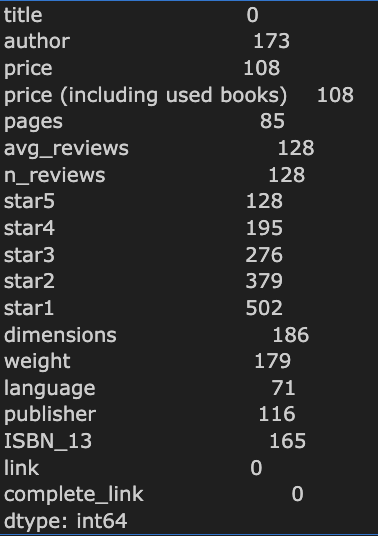
.isna.sum()으로 결측치가 몇개인지 살펴보니, 이런 결과가 도출되었습니다. 숫자형인 경우 결측치를 0으로 대체하면 되지만, 문자형인 경우 쉽지 않으므로 author가 결측치인 부분은 제거하도록 하겠습니다.
book_DataFrame = book_DataFrame[book_DataFrame['author'].notna()]로 author가 결측치인 부분을 제거하였습니다. 그리고 나머지 결측치는 모두 0으로 대체하였습니다.
### subsetting, star 1까지만 보도록 할게요!
#1. loc을 사용: book_DataFrame.loc[:, 'title' : 'star1']
#2. iloc을 사용
book_DataFrame = book_DataFrame.iloc[:, 0:12]
book_DataFrame.head()
그리고 subsetting하여 필요한 부분만 추출하였습니다. loc을 사용해도 되지만, 여기선 iloc을 사용하였습니다. 그리고 다시 데이터프레임의 모습을 확인합니다.

이렇게 잘 subsetting이 된 걸 볼 수 있습니다.
### Data Type 알아보기
book_DataFrame.dtypes
### title, author는 상관없으나 pages, star(n)은 숫자로 바꾸고 싶다!
book_DataFrame['pages'] = pd.to_numeric(book_DataFrame['pages'], errors='coerce')
book_DataFrame['star5'] = book_DataFrame['star5'].str.replace('%', '').astype(float)
book_DataFrame['star4'] = book_DataFrame['star4'].str.replace('%', '').astype(float)
book_DataFrame['star3'] = book_DataFrame['star3'].str.replace('%', '').astype(float)
book_DataFrame['star2'] = book_DataFrame['star2'].str.replace('%', '').astype(float)
book_DataFrame['star1'] = book_DataFrame['star1'].str.replace('%', '').astype(float)
print(book_DataFrame.dtypes)
book_DataFrame
그리고 각 열의 자료형을 확인해 보았습니다. 확인해 보았더니, pages와 star5, star4, star3, star2, star1 항목이 모두 object인걸 확인할 수 있었습니다. (pages에 경우에는 자료를 보니 어떤 열에서는 문자형이 존재하였고, star(n)의 경우에는 퍼센트 기호가 있어 object로 처리된 듯 합니다.) 따라서, 각각의 항목들을 다 실수 자료형으로 변경해 주었습니다. pages에 경우에는 numeric으로 바꾸되 바뀌지 않은 값들은 다 결측치 처리하도록 (errors = 'coerce') 하였고, star(n)의 경우에는 퍼센트 기호를 제거한 후 수로 처리하도록 하였습니다. 그랬더니 다시 결측치 값이 발생해, 다시 결측치 값을 0으로 채워 주었습니다.
### 결측치 0으로 다시 대체
book_DataFrame = book_DataFrame.fillna(0)
book_DataFrame
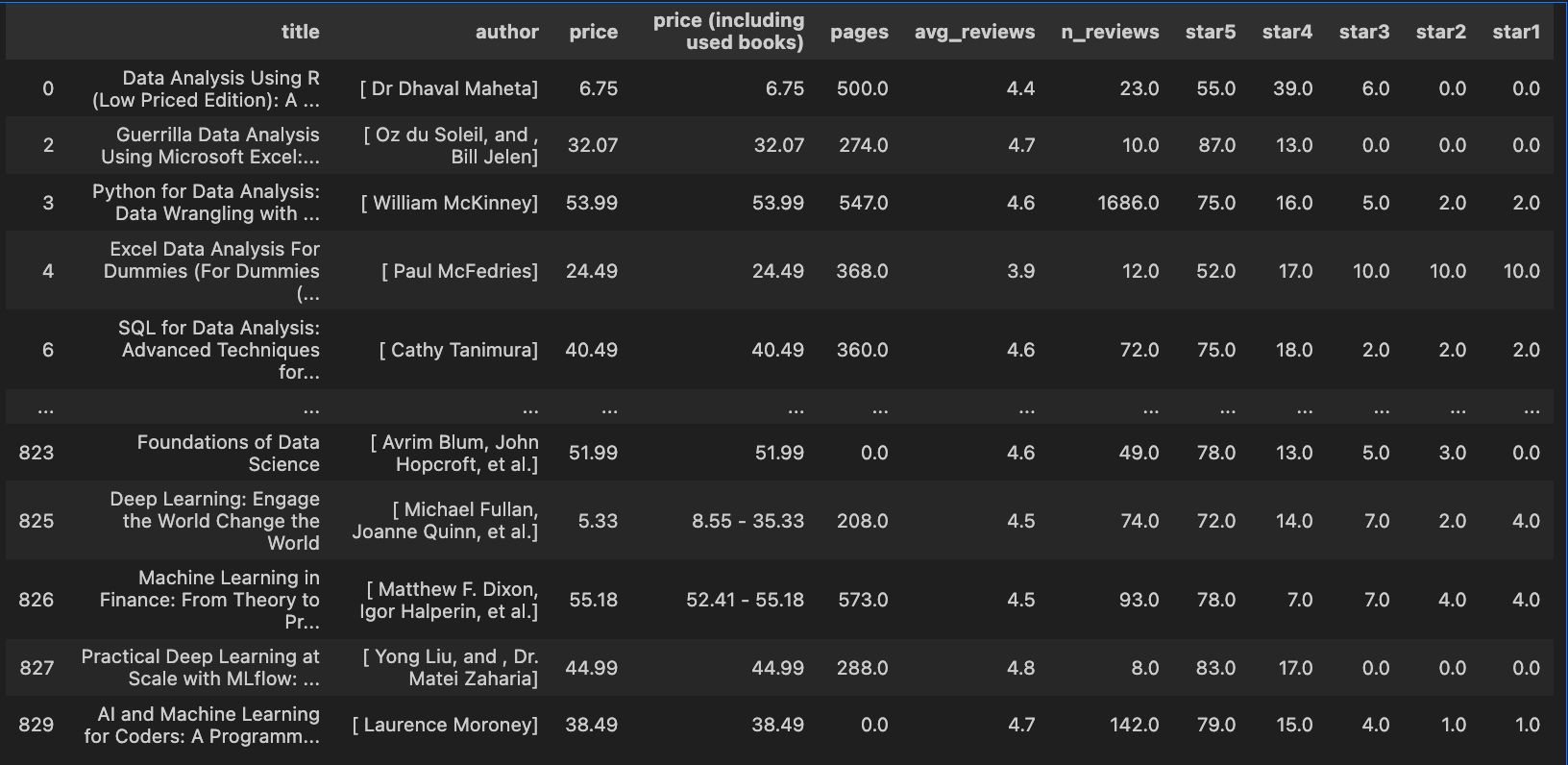
이렇게 잘 자료형이 변환된 걸 알 수 있습니다.
+ 새로운 열 만들어보기
이건 필요하지 않은 과정이긴 하지만, 연습을 위해 한 번 만들어 보았습니다.
### 새로운 열 만들어보기
## 페이지 당 가격 열 만들어보기
book_DataFrame["price_per_page"] = book_DataFrame["price"] / book_DataFrame["pages"]
새로운 열을 만들고 싶다면, 이렇게 추가하면 됩니다. 저는 페이지 당 가격 열을 추가해 보았습니다.
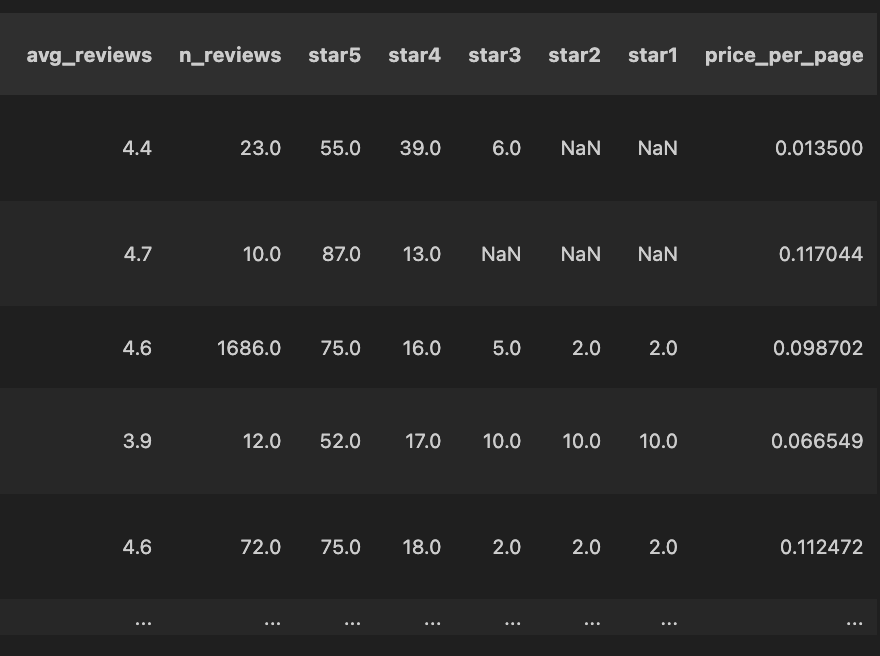
맨 오른쪽에, 새로운 열이 잘 추가된 것이 보입니다.
3. 결론 도출하기
### 그래프 만들어보기
import matplotlib.pyplot as plt
import seaborn as sns
### 하기 전에 20개 행만 추출해 보자
book_DataFrame = book_DataFrame[0:20]
그래프를 그려보기 위해 먼저 import matplotlib.pyplot과 import seaborn을 해 주었습니다. 그리고 이전에서 까먹고 진행하지 않은 행 20개 추출을 진행하였습니다.
먼저, '평균 별점이 어떻게 분포되어 있는가?' 를 보기 위해 히스토그램을 그려주었습니다.
#1. Histogram
book_DataFrame["avg_reviews"].hist(bins = 20)
plt.show()

별점은 4-5점에 걸쳐 분포된 것으로 보입니다. (0점에 모여있는 것들은 결측치 처리 때 0으로 처리해 생성된 가짜 0일 가능성이 높다고 생각합니다.) 그리고 4점 중반대가 가장 높고, 전반적으로 오른쪽으로 치우쳐진 모양을 띄고 있는 것을 볼 수 있습니다.
그리고 '각 책 별로 리뷰가 얼마나 많이 달려 있는가?' 입니다.
#2. Bar Plots
book_DataFrame.plot(kind = 'bar', title = 'number of reviews', x = 'title', y = 'n_reviews')

3권의 책에서 두드러지게 리뷰 수가 많은 것을 알 수 있습니다. 그 외에는 리뷰 수가 전부 400을 넘진 않네요.
그리고 '각 책 별로 평점 별점 5점, 4점, 3점은 얼마나 비율을 차지하고 있는가? 그 비율이 얼마나 되는가?' 입니다.
#.Line Graph
long_df = pd.melt(book_DataFrame, id_vars = 'title', value_vars = ['star5', 'star4', 'star3'], var_name = 'stars', value_name= 'rate')
sns.lineplot(data = long_df, x = 'title', y = 'rate', hue = 'stars')
plt.show()
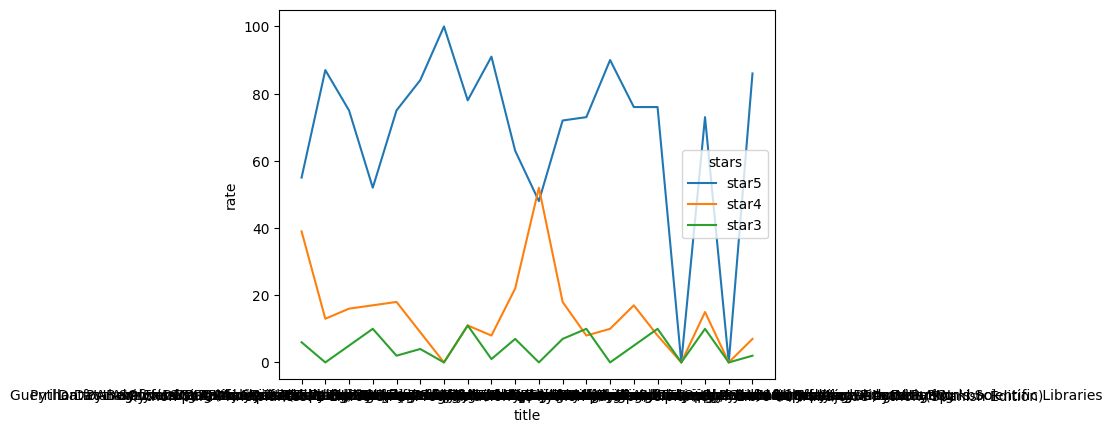
x축 레이블을 숨기는 방법을 몰라 차트가 조금 지저분합니다. 전반적으로 5점의 비율이 가장 높고, 그리고 4점, 그리고 3점의 비율이 높습니다. 5점이 압도적으로 많은 책도 있고, 4점의 수가 5점의 수를 초월한 책도 있네요. 5, 4, 3점이 모두 비슷한 비율로 존재하는 책도 있습니다.
마지막으로, '책의 가격과 페이지수 간의 상관관계가 있을까?' 입니다.
#scatterplot
sns.scatterplot(data = book_DataFrame, x = 'price', y = 'pages', size = 'n_reviews')

x축을 책의 가격, y축을 책의 페이지수로 놓고 보니 이런 결과가 도출되었습니다. 약한 선형성을 띄는 것으로 보아 상관관계가 약간은 있는 듯 합니다. 몇 아웃라이어를 제외하면, 보통 책의 페이지수가 많을수록 가격이 높은 양상이 있습니다.
이렇게 데이터셋에 대한 프로젝트를 진행해 보았습니다. 이번 프로젝트를 진행해 보며 느낀 점은,
1. 전처리 과정은 쉽지 않다. 자료에 대한 충분한 이해와 분석이 필요하다.
2. 무엇을 알고자 하느냐가 가장 중요하다.
3. 처음 해 본 프로젝트라 그런지 순서가 중구난방인 점이 아쉽다.
4. 통계학적 지식이 부족해 그래프 해석 능력이 낮은 점이 아쉽다.
5. 판다스를 좀 더 능숙하게 다루고 싶다.
입니다.
지금까지 봐주셔서 감사합니다 :) 다음 프로젝트는 좀 더 공부를 열심히 해서 돌아오도록 하겠습니다!